
AI 모델의 성능(인식률)을 높이는 방법에는 여러 방법이 있지만 나는 가장 간단한 방법 2가지를 사용했다
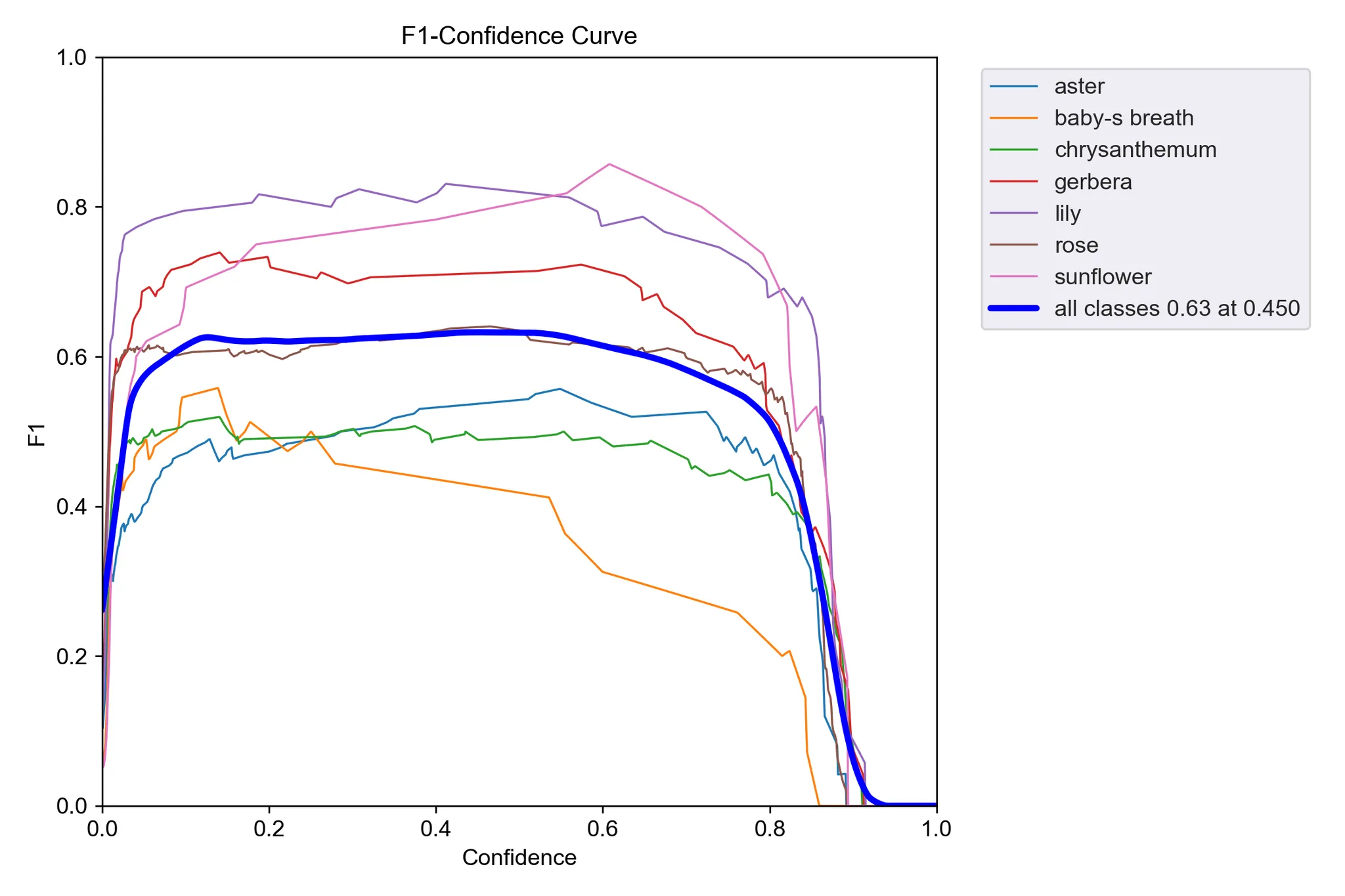
그전에 모델 성능 지표를 간단하게 확인할 수 있는 F1 Score Curve를 알아보자

- 의미: 재현율(Precision)과 정밀도(Recall)의 조화 평균을 나타낸 곡선
- 높을수록 좋은 성능을 의미하며, 일반적으로 1에 가까울수록 좋다
- 사용자의 그래프 분석:점수가 낮거나 들쭉날쭉하면 Precision과 Recall 사이에 균형이 맞지 않음
- 보통 0.8 정도의 수치가 나오면 좋은 성능을 가진 모델이라고 할 수 있음
- F1 점수가 일정하게 높으면 모델의 균형이 잘 잡힌 것
데이터셋 품질 및 수량 향상
Flower Classification Object Detection Dataset (v5, 2024-12-14 11:43pm) by viskom
274 open source Flowers images and annotations in multiple formats for training computer vision models. Flower Classification (v5, 2024-12-14 11:43pm), created by viskom
universe.roboflow.com
기존 200-300 장 정도의 데이터셋 사진 수를 4000장 정도로 늘려주었다! 물론 그만큼 모델학습 시간은 길어지겠지만
공부량이 많으면 성적의 저점이 낮아지듯, 무식하지만 가장 좋은 방법 중 하나임
v0.1_flower_yolov5_640..? #1
맨 처음 모델학습할 때는 데이터셋 라벨링, 하이퍼파라미터, 이런 거 모르고 무작정 오 학습된다! 하고 좋아했는데
정작 학습이 된다고 모델의 성능까지 좋은 건 아니었다. 성적이 안 나와도 날 격려해 주던 울 엄마의 마음이 이랬을까

이후 같은 데이터셋으로 하이퍼 파라미터를 좀 만지면서 이렇게 저렇게 학습을 해봤는데 생각보다 성적이 잘 나오지 않았다
v0.3_flower_yolov5_640_b32_ep100 #3
이때부터 모델 구분하려고 모델 폴더 이름에 하이퍼 파라미터값을 같이 써뒀다.
이제 roboflow에서 같은 classes들을 가진 데이터셋 이미지를 대량으로 받아와 약 3000장 정도 되는 이미지들과 라벨링 파일을 기존 학습이미지와 합쳐서 학습을 진행해 봤다.
하이퍼 파라미터 조정
v0.4_ flower_yolov5_640_b16_ep100 #4
python train.py --img 640 --batch 16 --epochs 100 --data flowerDataset_2\data.yaml --weights yolov5s.pt --name flower2_yolov5_b16_ep100batch (배치 크기) : 한 번의 학습 단계에서 처리되는 데이터 샘플의 수
작게 설정: 메모리 사용량 감소, 더 자주 가중치 업데이트. 하지만 학습이 불안정할 수 있음.
크게 설정: 학습이 안정적이지만, 더 많은 메모리가 필요하고 학습 속도가 느려질 수 있음.
GPU 메모리 용량에 따라 설정하고 너무 크게 하면 학습하다가 중간에 꺼져버린다.
일반적으로 16, 32, 64 등 2의 배수로 설정한다고 한다.
epochs (에포크 수) : 전체 데이터셋을 한 번 모두 학습하는 횟수
작게 설정: 학습이 충분하지 않아 과소적합 가능성.
크게 설정: 학습이 과도해 과적합 가능성.
데이터셋 크기와 복잡도에 따라 설정하고 일반적으로 50~300 사이에서 테스트하며 최적 값을 찾는다고 함
학습 파라미터를 여러 개 조정해 본 결과 이렇게 학습한 게 제일 결과도 나름 잘 나왔고 여기서 더 높은 파라미터를 설정하면 너무 오래 걸림 + 그래픽카드가 견디지를 못해서 이 버전을 최종적으로 사용하기로 함!


데이터셋 이미지를 대폭 확대하니 Epoch 하나를 학습하는데 30초 이상 소요됨
30초 * 100 Epoch = 3000초 = 50분 정도로 학습시간이 대폭 길어짐
집 앞에 버거킹 가서 햄버거 세트하나 먹고 왔는데도 학습하고 있어서 놀랐음

약 한 시간 정도 4000개의 이미지 데이터셋을 기반으로 100 Epoch 학습을 돌린 결과
전체적으로 70-80% 적중률의 준수한 성능의 모델이 뽑힘!
mAP@0.5: 80.8%로, IoU 0.5 기준에서 모델의 평균 정확도
mAP@0.5:0.95: 66.3%로, 더 엄격한 IoU 기준에서의 평균 정확도
Precision(P): 77.3%로, 모델의 예측 중 올바른 비율
Recall(R): 74.1%로, 실제 객체를 얼마나 잘 탐지
테스트해봅시다
학습이 잘됐다면, runs/train/ 경로에 본인이 학습했던 모델폴더가 있을 텐데 그럼 이제 테스트를 해볼 수 있다
test_images/라는 경로를 만들어, 테스트하고 싶은 이미지들을 여러 개 넣어주자

yolov5 폴더경로에 있는 detect.py 를 사용한다!
python detect.py --weights runs/train/flower2_yolov5_b16_ep100/weights/best.pt --img 640 --conf 0.4 --source test_images/-img : 학습할 때 쓴 이미지 크기 -> 640으로 학습했으니 640으로 test
-conf : 신뢰도 threshold (0.25~0.5 사이 )
-source : 테스트할 이미지 폴더
 |
 |
이 정도 인식률이면 훌륭한 듯하다, 내가 할 프로젝트는 엄청나게 정확한 인식률이 요구되는 게 아니기 때문에
이 정도에서 모델학습을 마무리하고, 이제 이 모델파일을 백엔드랑 연동하는 방법을 공부해야 함
flask 서버 + yolov5 모델연동
그래도 첫 AI모델까지 만들었는데 웹개발자로서 테스트를 안 해볼 수 없었음, 얼른 연동하고 싶어서 막 신이 나더라고요
그전에 flask와 yolo모델의 호환성을 위해 파이썬 가상환경 위치를 파일 최상단으로 옮겨주고 같이 사용하기로 함!

간단하게 backend아래에 app.py 만들어주고 파일경로만 잘 맞춰주면 기본 구조 만들기는 간단합니다
모델 이미지 분석 요청
- Method: POST
- URL: http://localhost:5000/predict
- Content-Type: multipart/form-data
- Body:
- image: 업로드할 이미지 파일 (File 타입)
from flask import Flask, request, jsonify, send_file
import os
import torch
from pathlib import Path
from yolov5.detect import run # YOLOv5 내부 detect->run 호출
app = Flask(__name__)
# 모델 경로
MODEL_PATH = 'yolov5/runs/train/flower2_yolov5_b16_ep100/weights/best.pt'
@app.route('/')
def index():
return 'YOLOv5 꽃다발 인식 서버가 실행 중입니다!'
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': '이미지가 필요합니다.'}), 400
file = request.files['image']
filename = 'input.jpg'
filepath = os.path.join('static', filename)
file.save(filepath)
# YOLOv5 예측 실행
run(weights=MODEL_PATH, source=filepath, imgsz=(640,640), conf_thres=0.4, save_txt=False, save_conf=False, project='static', name='detect', exist_ok=True)
result_path = Path('static/detect/input.jpg')
if result_path.exists():
return send_file(result_path, mimetype='image/jpeg')
else:
return jsonify({'error': '예측 실패'}), 500
if __name__ == '__main__':
os.makedirs('static', exist_ok=True)
app.run(debug=True)python app.py해서 실행해 주면

postman으로 request 해도 200OK로 잘 작동되는 걸 확인!
로컬 테스트는 끝났고 이제 이거를 어떻게 서비스하냐가 문제인데 Docker를 사용해서 한 번에 묶어서 배포해 버릴까 생각 중
근데 문제는 Docker를 사용해 본 적이 없어서 공부와 동시에 웹서핑+삽질을 열심히 해봐야 할 듯함 ㅠㅠ