[Dev] YOLOv5 Custom Training : GPU로 Roboflow 데이터셋을 학습시켜보자 (window11, RTX3060Ti) #1
졸업작품으로 언젠가 해보고 싶었던 AI 모델학습을 직접 해보기로 했음!
작년에 선배들 졸업작품 전시회랑 학술제들을 둘러보다가 YOLO라는 이미지 기반 AI모델을 활용해 모델학습을 시켜서
사용자 이미지에 매핑하는걸 처음 봤는데 엄청 신기했던 거임
잘만 사용하면 웹캠이나 cctv 같은 거에 연동해서 사물인터넷이나 실사용 시스템을 만들 수도 있겠다 싶었음
실제로 모델학습에 대한 공부 없이 노 베이스로 박치기해보려고 했는데 유튜브랑 다른 블로그 글 이것저것 봐도 google coleb을 주로 많이 쓰던데, 로컬 pc에서 GPU 써가지고 직접 학습시키는 내용은 많이 없었음
계획하고 있는 졸작이 학습한 모델로 백엔드서버랑 연동해서 웹사이트까지 만드는 거라
그냥 로컬에 갖고 있으면서 돌리는 게 편할 듯했음
colab.google
Colab is a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs. Colab is especially well suited to machine learning, data science, and education.
colab.google
cpu로만 학습할 수도 있지만 비싼 돈 주고 산 gpu 이럴 때 써먹어야 한다는 마인드로
맥북 안 쓰고 윈도 데스크톱에서 꾸역꾸역 공부하면서 설정했음
사실 144 프레임으로 게임하려고 그래픽카드 산 건데! 공부도 하면 얼마나 좋아, 환경설정하고 삽질하고 기본 모델학습 하는 데에만 하루 삽질한 듯 ㅎㅎㅎ ㅠ
음 일단 목차를 좀 나눠보자
python 3.8 설치
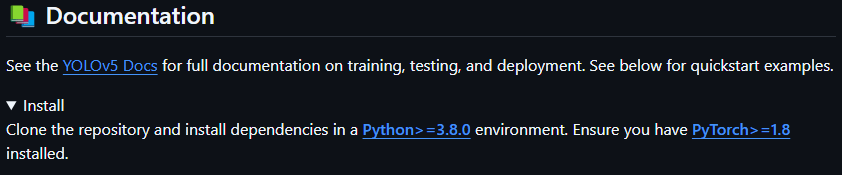
YOLOv5 공식 깃허브 문서에 파이썬 3.8.0 이상버전, pyTorch 1.8 버전 이상으로 하라고 합니다.
항상 개발환경은 최신버전보다는 하라는 대로 하는 게 이슈없이 편하더라고요
Python Release Python 3.8.10
The official home of the Python Programming Language
www.python.org
맨 아래로 내려가서 맞는 운영체제로 받아주고

그리고 꼭 터미널 가서 명령어 쳐주고 현재 파이썬이 뭐로 잡히는지 확인해줘야 함
python --version
# Python 3.8.10YOLOv5 소스코드 내려받기
YOLOv5 공식 깃허브로 가서
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
github.com

ZIP file로 다운로드하여 압축을 풀어주고 잘 놔둡시다
홈
Ultralytics YOLO - 실시간 물체 감지 및 이미지 분할의 최신 기술을 살펴보세요. 기능을 알아보고 프로젝트에서 그 잠재력을 극대화하세요.
docs.ultralytics.com
공식 YOLO 한국어 문서도 있다!
여기까지 하고 vscode에 방금 압축 풀었던 yolov5-master를 가져온 다음
관리자 권한으로 터미널을 실행한 다음 개발환경 위치로 가준다

yolov5-master <- 폴더 이름 바꿔도 되는데, 나는 여러 번 실패해서 다시 하느라 바꾸는 걸 까먹었다
그냥 VScode 안에 있는 터미널 쓰면 안 되나요?
-> 될 수도 있는데 관리자 권한 때문에 중간에 막히는 부분이 몇 번 있어서 처음부터 키는 게 편한 것 같음
이제 python 라이브러리 가져올 게 많은데, 다른 파이썬 라이브러리들과 충돌 나지 않게 가상 python 환경을 만들어주자
# Python 가상환경(.venv) 설정
1 -> python -m venv {가상환경 폴더 이름}
# activate
2 -> {가상환경 폴더 이름}\Scripts\activate
# 종료하고싶으면
deactivate
나는 가상환경 폴더 이름을. venv로 했다
activate 한 다음 터미널 경로 앞에 (. venv)처럼 폴더 이름이 나오면 굿
pip install -r .\requirements.txt위 명령어를 입력해 yolov5 구동에 필요한 패키지들을 한 번에 설치해 주자
Roboflow 데이터셋 가져오기
이제 AI 모델에게 학습시킬 이미지 데이터가 필요하다!
Roboflow: Computer vision tools for developers and enterprises
Everything you need to build and deploy computer vision models, from automated annotation tools to high-performance deployment solutions.
roboflow.com
Roboflow라고 다양한 분야의 데이터셋을 올려둔 깃허브 같은 느낌인데 이미지 라벨링까지 다 되어있는 감사감사한 데이터셋들이 많으니 이미지들 직접 라벨링툴로 한 땀 한 땀 딸 거 아니면 여기서 구하는 거를 가장 추천함..!
Flower Classification Object Detection Dataset (v5, 2024-12-14 11:43pm) by viskom
274 open source Flowers images and annotations in multiple formats for training computer vision models. Flower Classification (v5, 2024-12-14 11:43pm), created by viskom
universe.roboflow.com
나는 꽃다발이랑 꽃 이미지 데이터셋을 여러 개 합쳐서 학습시켜 서비스를 만들거라 적당한 꽃 데이터셋을 가져왔다



Download Dataset을 누르고 YOLO v5 PyTorch format으로 컴퓨터에 zipfile 다운하면 된다

trains/images 에 가보면 이런 샘플 이미지들이 잔뜩 있으면 오케이, 그리고 이미지 숫자에 맞게 labels 폴더에도

이렇게 라벨 txt 파일들이 잔뜩 있으면 된거다

이렇게 YOLO github에서 받은 폴더, dataset 폴더 하나씩 준비해 두고


YOLO 폴더/data/{데이터셋폴더 이름}을 만들고
그 안에 데이터셋의 train 폴더와 valid 폴더, data.yaml을 가져와준다 (test는 필수 아님)
그다음 data.yaml 에 가서 데이터셋 폴더를 연결해주어야 하는데 이거를 절대경로로 설정하는 게 좋다
train: 'C:\Users\username\Desktop\yolov5-master\data\flowerDataset\train\images'
val: 'C:\Users\username\Desktop\yolov5-master\data\flowerDataset\valid\images'
nc: 7
names: ['aster', 'baby-s breath', 'chrysanthemum', 'gerbera', 'lily', 'rose', 'sunflower']이런 식으로 train과 val의 경로를 절대경로로 설정해 주자
cpu로만 학습할 거라면 이제 여기서 학습시작 명령어를 입력해도 될 거임
python train.py --img 640 --batch 8 --epochs 50 --data data/데이터셋폴더/data.yaml --weights yolov5s.pt --device cpu
- --img 640 → 입력 이미지 크기 (640x640 권장)
- --batch 8 → 배치 크기 (CPU라면 낮은 값 추천, ex: 16~8)
- --epochs 50 → 학습 에포크 수 (50번 학습)
- --device cpu → cpu로 학습
이 밑은 이제 GPU 사용해 Custom Training 하는 환경설정법
CUDA, cuDNN설치
더욱 빠른 학습이 필요하다면 놀고 있는 GPU를 일하게 하자, CPU 단일 연산보다 10~20배는 학습이 빨라지니!
cpu연산속도보다 10배 빠르게 gpu환경설정을 한다면 장기적으로 봤을 때 개이득이 아닐까?라는 생각이지만
cuda와 pytorch 용량이 꽤 나가니 여유롭게 설치하자
nvidia-smi
터미널에 명령어를 쳐서 본인 그래픽카드가 잡히는지, CUDA version이 몇인지 인지하고 있는 게 좋다
CUDA Toolkit 12.1 Downloads
Get the latest feature updates to NVIDIA's proprietary compute stack.
developer.nvidia.com

windows 10이면 10, windows 11 이면 11 선택, exe(network) 선택해서 다운로드

똑같이 cuDNN도 설치해 주면 된다
cuDNN 9.8.0 Downloads
developer.nvidia.com
Pytorch 설치
나는 CUDA 12.8 제일 최신버전이라 현재 윈도우에서 지원하진 않는다고 해서 12.4로 깔았다
본인 CUDA 버전에 맞추어 터미널에서 pytorch를 깔아주자 이건 조금 오래 걸리니 커피 한 잔 타와도 된다
PyTorch
pytorch.org

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
다 깔고 나서 터미널에 아래 명령을 쳐보자
python -c "import torch; import torchvision; print('torch:', torch.__version__, 'torchvision:', torchvision.__version__); print('CUDA:', torch.cuda.is_available())"
이런 식으로 torch 버전과 CUDA 상태가 잘 나온다면 오케이
트러블슈팅(troubleshooting)
최종 학습환경
| torch | 2.4.1+cu124 ✅ |
| torchvision | 0.19.1+cu124 ✅ |
| CUDA 사용 가능 | True ✅ |
나는 아래 명령으로 모델학습을 진행했다.
python train.py --img 640 --batch 16 --epochs 50 --data flowerDataset\data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name flower_yolov5_results--name : 학습결과를 저장할 폴더 이름
처음에는 에러가 너무 많이 나와서 내가 잘못한 건지 설치를 안 한 건지 몰랐는데 하나하나 뜯어보니 common.py이랑 train.py 파일에 문법오류가 있어서 나는 문제였다.
1.
\models\common.py:906: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with amp.autocast(autocast):# 기존 코드 906번줄?
with amp.autocast(autocast):
...
# 수정된 코드
with torch.amp.autocast(device_type='cuda', dtype=torch.float16 if amp else torch.float32):
...2.
train.py:412: FutureWarning: torch.cuda.amp.autocast(args...) is deprecated.
Please use torch.amp.autocast('cuda', args...)
instead. with torch.cuda.amp.autocast(amp):
0/49 11.2G 0.0946 0.1029 0.05498 164 1184: 97%|█████████▋|
35/36 [01:17<00:02, 2.train.py:412: FutureWarning: torch.cuda.amp.autocast(args...) is deprecated.
Please use torch.amp.autocast('cuda', args...)특히 torch.amp.autocast('cuda', args...) 오류가 나를 괴롭혀서 삽질을 많이 했는데 뜯어보니 함수 반환타입 에러였다.
TypeError: set_autocast_dtype(): argument 'dtype' (position 2) must be torch.dtype, not bool
torch.amp.autocast('cuda', amp) 구문에서 잘못된 데이터 타입(bool)이 전달되었기 때문에 발생
2번째 들어가는 형식이 bool type이 아니라 dtype이라는 거임..
# train.py에서 문제가 발생한 코드:
with torch.amp.autocast('cuda', amp):
# 해결한 코드
with torch.amp.autocast(device_type='cuda', dtype=torch.float16 if amp else torch.float32):
# device_type='cuda' → GPU에서 자동 혼합 정밀도 연산을 활성화
# dtype=torch.float16 → float16을 사용하여 연산 속도 최적화이걸로 마참내 해결!
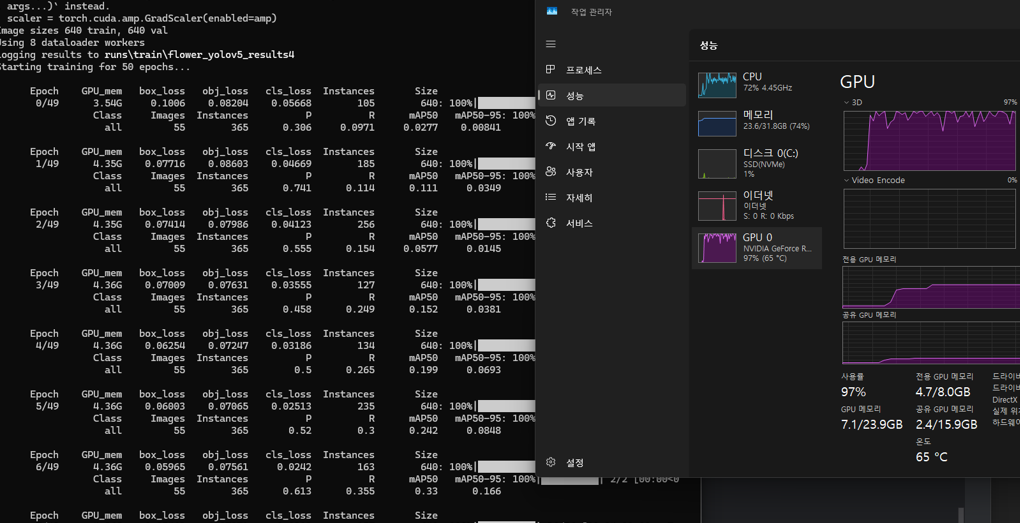
CPU랑 GPU랑 같이 열심히 연산하며 일하고

성공적으로 모델학습이 완료되면 runs라는 폴더 안에 모델학습 데이터들이 이렇게 남게 됨
TensorBoard 라이브러리도 깔아서 모델학습 실시간 시각화도 해봤음

이제 모델 학습은 어느 정도 감을 잡았으니 여러 개 데이터셋을 준비해서 학습시키고 활용하는 방법을 공부해야겠음